1. 说明
数据填充 时,要特别注意 php artisan db:seed 的运行效率,否则随着项目的代码量越来越大,db:seed 的运行时间会变得越来越长,有些项目多达几分钟甚至几十分钟。
只有在 db:seed 运行起来很快时,才能完全利用数据填充工具带来的便利,而不是最后变成累赘。
2. 模型工厂
Laravel 的官方文档中,建议 使用模型工厂来填充数据 。在日常使用中,需要注意以下几点。
2.1 避免使用 create 方法
使用 模型工厂函数 编写假数据插入逻辑时,要注意避免使用 create 方法,因为每一次都是一条 SQL 语句。
factory(\App\Models\User::class)->times(300)->create();以下截图是一个使用 factory 辅助函数的例子,插入 300 条数据,总共执行了 602 条 SQL 语句,总执行时长为 23.91 秒。
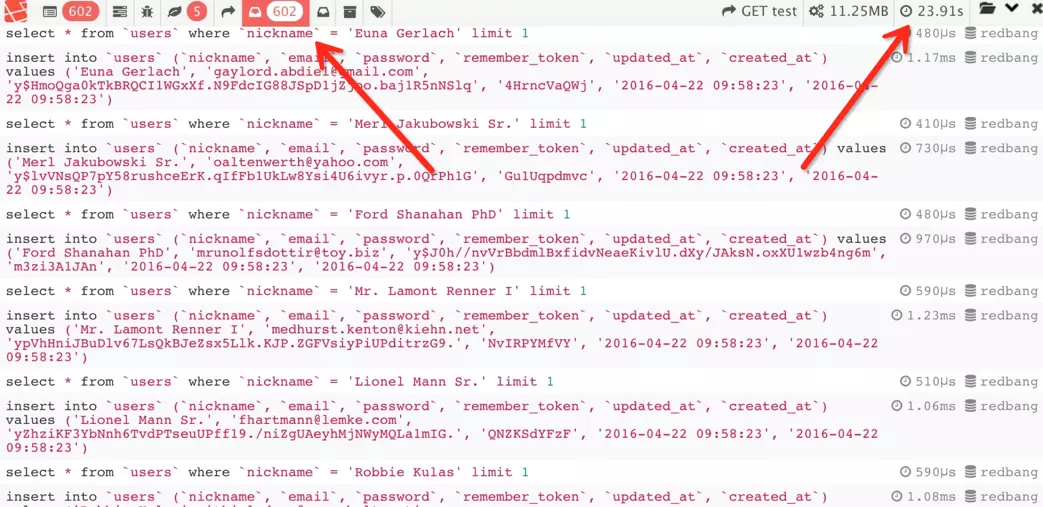
轻轻松松运行时间就累积起来了,你能想象运行一次 db:seed 要半个小时是什么感觉么?

2.2 应使用 make 方法
$users = factory(\App\Models\User::class)->times(1000)->make();
\App\Models\User::insert($users->toArray());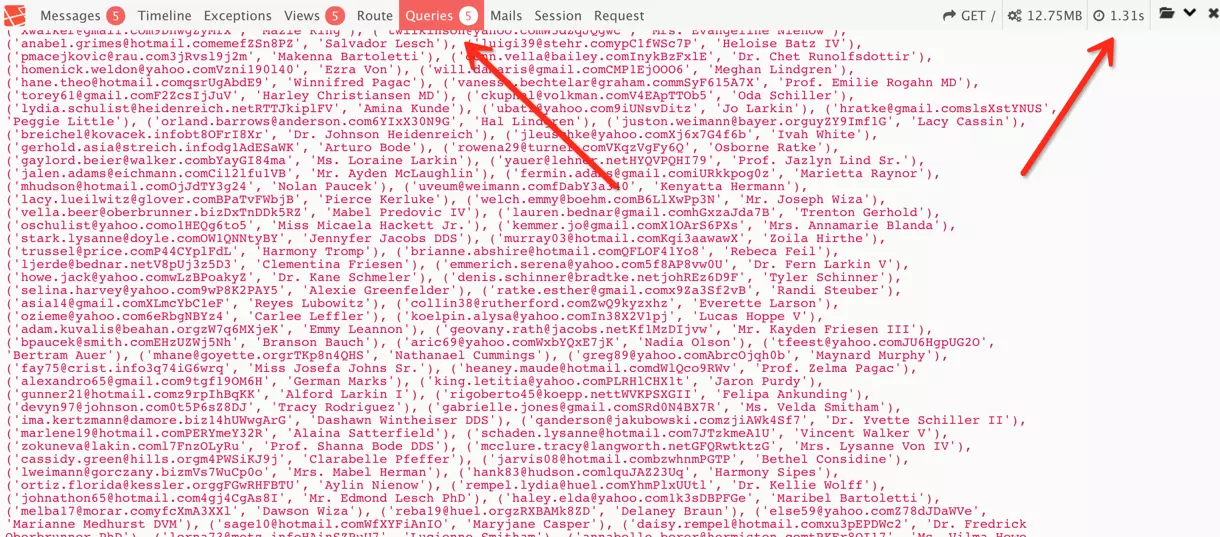
3. 传统方式
3.1 一个错误的例子
下面代码执行了 1000 条 SQL 语句,在书写数据填充的时候,也是要尽量避免:
$faker = Faker::create();
$users = User::lists('id');
foreach (range(1, 1000) as $index)
{
Topic::create([
'user_id' => $faker->randomElement($users),
'title' => $faker->sentence(),
'description' => $faker->text(),
]);
}3.2 解决方案
使用 DB:insert,直接快速,一步到位:
$faker = Faker::create();
$users = User::lists('id');
$datas = [];
foreach (range(1, 1000) as $index)
{
$datas[] = [
'user_id' => $faker->randomElement($users),
'title' => $faker->sentence(),
'description' => $faker->text(),
'created_at' => Carbon::now()->toDateTimeString(),
'updated_at' => Carbon::now()->toDateTimeString(),
];
}
DB::table('topics')->insert($datas);只有 db:seed 运行起来很快的时候,你才可以随时随地,想 seed 就 seed。